第 6 章 记忆管理和上下文工程
- 理解 智能体记忆系统的认知科学基础,区分工作记忆、短期记忆、长期记忆、情景记忆的特点与功能
- 理解 上下文工程范式的核心思想,掌握从「存储导向」到「检索导向」的范式转变
- 应用 U 型注意力曲线原理优化信息放置策略,最大化关键信息的召回率
- 应用 三层信息架构(L1/L2/L3)和四策略框架进行上下文优化
- 分析 不同压缩策略的代价与收益,选择适合任务特征的压缩方法
- 创造 设计具有分层记忆架构的智能体系统,实现短期、中期、长期记忆的协同管理
- 评价 在给定场景中评估记忆管理策略的成本效益,平衡信息保留与上下文空间
想象这样一个场景:你是某私人银行的智能理财顾问,正在服务一位 VIP 客户。客户三个月前曾表达过对 ESG 投资的兴趣,上周讨论了孩子的教育金规划,今天又提到想了解海外资产配置。如果你记不住这些对话历史,每次都要客户从头解释需求,服务体验会大打折扣。
这就是本章要解决的问题:如何让智能体具备高效的记忆能力?
记忆管理看似只是「存储数据」,但深入思考后你会发现:关键不是存多少,而是在正确的时间找到正确的信息。这就是「上下文工程」的核心思想——它不追求无限大的上下文窗口,而是追求高信号密度的信息检索。
本章将从认知科学出发,建立智能体记忆的四层架构:工作记忆(上下文窗口)、短期记忆(会话历史)、长期记忆(外部存储)、情景记忆(决策轨迹)。然后深入探讨上下文工程的核心技术:U 型注意力曲线、缓存优化、压缩策略、分区策略。最后通过一个真实的「自我进化 AI 副本」案例,展示所有概念如何在实践中协同工作。
6.1 记忆管理概述
想象一位资深理财顾问与客户的对话。客户张先生走进办公室,顾问立刻说:您上次提到计划三年内买房,最近房价有所松动,要不要聊聊购房首付的配置?这位顾问之所以能提供如此贴心的服务,关键在于他记住了客户的核心需求。
智能体也面临同样的挑战。没有记忆的智能体,每次对话都是从零开始——它不记得你上周问过什么,也不知道你偏好稳健还是激进的投资风格。这样的智能体只能充当一次性的问答工具,无法成为真正的知识伙伴。
本节我们将从认知科学出发,理解人类记忆的工作原理,建立智能体记忆系统的整体框架,并引入上下文工程这一新范式。
6.1.1 为什么智能体需要记忆
在金融服务场景中,记忆能力直接决定了智能体的服务质量。
场景一:无记忆的客服困境
第一天: - 客户:我想了解债券基金和股票基金的区别。 - 智能体:[详细解释两类基金的风险收益特征]
第二天: - 客户:那个收益稳定的基金叫什么来着? - 智能体:请问您指的是哪种基金? - 客户(不耐烦):就昨天聊的那个啊! - 智能体:对不起,我没有昨天的对话记录…
第三天: - 客户:我考虑清楚了,就买那个稳健的。 - 智能体:您好,请问需要购买什么产品? - 客户:[关闭对话]
这种「健忘」的体验令人沮丧。客户不得不重复说明自己的需求,交流效率大打折扣。
场景二:有记忆的智能顾问
同样的客户第二天继续咨询:
智能体主动提示:您昨天询问了债券基金,它的特点是收益相对稳定、波动较小。您的风险偏好是保守型,建议关注中短期纯债基金。需要我推荐几只具体产品吗?
这才是真正有价值的金融服务。记忆让智能体从「工具」进化为「伙伴」。
记忆能力的商业价值体现在三个维度:
- 客户留存率:记住偏好的智能体能提供个性化服务,客户黏性更强
- 服务连续性:跨会话保持知识积累,避免重复沟通
- 决策一致性:基于历史经验做出稳定判断,而非每次从零开始
6.1.2 记忆的认知科学基础
要设计智能体的记忆系统,我们先看看人类大脑是如何管理记忆的。认知神经科学研究揭示,人类记忆系统存在多个层次,各层次分工明确、协同工作。
感觉记忆
这是信息进入大脑的第一站。当你看一眼股票报价屏,所有数字都会短暂停留在视觉系统中——但仅仅持续几百毫秒。绝大多数信息在这个阶段就被遗忘,只有你注意到的内容才会进入下一层。
短期记忆
你刚听到的电话号码、刚看到的验证码,都存储在短期记忆中。它的容量有限,心理学经典研究表明,人类短期记忆大约只能容纳 7±2 个信息单元。更重要的是,这些信息很快就会消失——如果不加复述,几十秒后你就忘了刚才的验证码。
工作记忆
这是大脑的「在线处理器」。当你心算 23×17 时,你需要同时记住 23、17、中间结果 21(7×3)、161(7×23)等数字,并按照乘法规则进行运算。这个过程就发生在工作记忆中。
工作记忆与短期记忆的本质区别:短期记忆只负责「存储」,而工作记忆不仅存储,还能「处理」——它可以主动调用长期记忆中的知识,进行逻辑分析和推理。
心理学家 Baddeley 提出的工作记忆模型包含三个子系统:语音环路(处理语言信息)、视空间画板(处理图像信息)、中央执行系统(协调整合)。这个模型对智能体设计有重要启发。
长期记忆
你的母语词汇、骑自行车的技能、童年的重要经历——这些都存储在长期记忆中。它的容量几乎无限,保存时间可达数十年。但长期记忆的写入需要时间和重复,检索也可能失败(想想那些话到嘴边却想不起来的时刻)。
6.1.3 智能体记忆的四层架构
借鉴人类记忆系统的分层设计,智能体的记忆架构也可以分为四个层次。
| 人类记忆 | 智能体对应 | 持续时间 | 容量 | 典型内容 |
|---|---|---|---|---|
| 工作记忆 | 上下文窗口 | 任务期间 | 200K tokens | 当前任务描述、系统提示、相关文档摘要、工具输出 |
| 短期记忆 | 会话历史 | 会话期间 | 会话级 | 完整问答对、中间推理过程、临时变量 |
| 长期记忆 | 外部存储 | 持久 | 无限 | 用户画像、知识库、项目配置、历史报告 |
| 情景记忆 | 决策日志 | 选择性持久 | 按需 | 决策轨迹、市场情境标签、经验教训、反思记录 |
工作记忆:智能体的「心理白板」
智能体处理任务时,需要把相关信息加载到上下文窗口中。这就像你在白板上写下要点,一边看一边思考。上下文窗口的大小决定了智能体能同时「看到」多少信息——Claude Sonnet 4 的上下文窗口是 200K tokens,相当于一本中等篇幅的书。
但白板面积有限。当信息太多时,你必须擦掉一些内容,为新信息腾出空间。智能体也是如此——上下文管理是记忆系统的核心技能。
短期记忆:会话历史
从对话开始到结束,所有的问答记录都保存在短期记忆中。它保证了对话的连贯性:当客户说「就选这个」时,智能体知道「这个」指的是刚才讨论的那只基金。
长期记忆:跨会话持久化
会话结束后,重要信息需要保存到外部存储(文件、数据库)。下次客户再来咨询时,智能体可以检索这些记忆,接续之前的服务。
情景记忆:决策轨迹
这是一种特殊的长期记忆,存储的不是「知识」,而是「经历」。比如,智能体记录了「2024 年 8 月 15 日,客户想在科技股大涨时追高买入,我建议分批建仓,客户采纳后平均成本降低 2.5%」。当类似情况再次出现时,智能体可以借鉴这段经验。
6.1.4 上下文工程:从存储到检索的范式转变
传统的记忆管理思维是「如何存储更多」——追求更大的上下文窗口、更多的存储空间。但这种思路存在根本性缺陷。
传统思维:如何存储更多信息?
新范式:如何在正确的时间检索正确的信息?
核心洞见:记忆的价值在于检索,而非存储。
为什么更大的窗口不能解决问题
直觉上,我们以为更大的上下文窗口意味着更好的记忆。但研究表明并非如此:
- 注意力稀释:窗口越大,每个位置分到的注意力越少
- 训练分布偏移:模型训练时短序列占主导,长序列经验不足
- 成本不成比例增长:双倍 tokens 带来的可能是超过双倍的成本和延迟
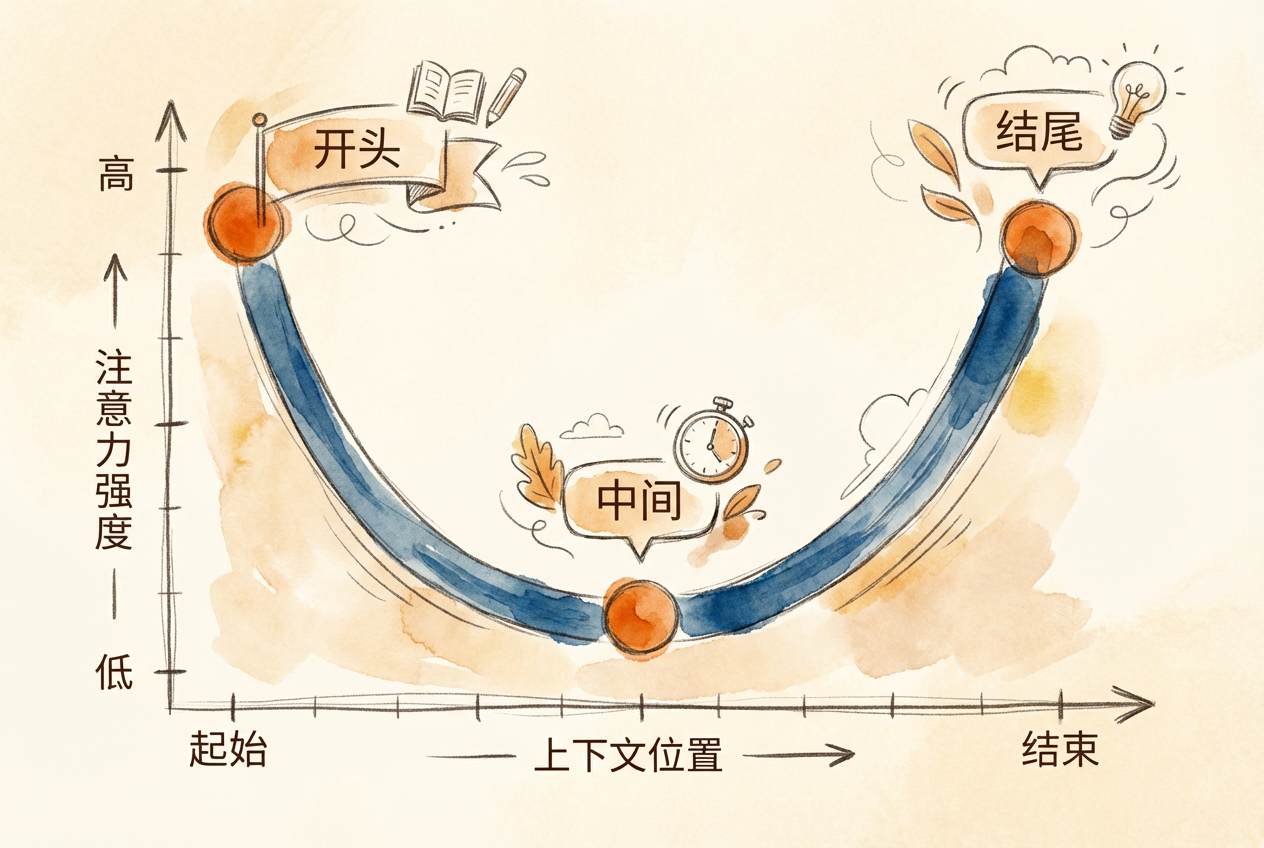
研究发现,Transformer 模型的注意力分布呈 U 型曲线:开头和结尾的信息召回率最高,中间区域下降 10-40%。这意味着关键信息应放在系统提示(开头)和当前任务描述(结尾),而非中间位置。
RULER 基准测试发现:声称支持 32K+ tokens 上下文的模型中,只有 50% 能在 32K 时保持满意性能。
约束优化框架
上下文工程是一个优化问题:
- 目标函数:最大化输出质量
- 约束条件:令牌预算、延迟要求、成本限制、注意力容量
- 决策变量:什么信息进入上下文、放在什么位置、以什么形式
上下文窗口是具有机会成本的经济资源。把所有可能有用的信息塞入上下文,就像把所有资产都变成现金持有——流动性最大化,但收益最低。
令牌分配类似于投资组合配置:在有限资源下追求最优收益。每个 token 都有成本(金钱和注意力),需要精心配置。
上下文工程的核心任务
找到最小的高信号 token 集合,最大化期望输出质量。这个定义包含两层含义:
- 最小化:不是越多越好,而是恰到好处
- 高信号:相关性和信息密度比数量更重要
这个范式转变对记忆系统设计有深远影响。在后续章节中,我们将学习如何通过压缩、缓存、分层加载等技术,实现高效的上下文管理。
6.5 情景记忆:决策轨迹与自我进化
交易执行智能体在复盘会议上被问到:2024 年 8 月 15 日那笔科技股交易是怎么决策的?如果它只记得最终结果(买入 1000 股,收益 12%),这个问题无法回答。但如果它记住了完整的决策过程——市场信号、分析逻辑、备选方案、最终选择——它就能像一位经验丰富的交易员一样复盘。
这就是情景记忆(Episodic Memory)的独特价值。它不同于「知道什么」的事实性知识,而是关于「经历了什么」的亲身体验。对于智能体而言,情景记忆是实现经验学习和类比推理的关键。
6.5.1 情景记忆的独特价值
情景记忆与长期记忆有本质区别。长期记忆存储的是「通货膨胀会侵蚀购买力」这样的知识;情景记忆存储的是「2024 年 8 月 15 日,我因为担心市场过热而建议客户分批买入科技股,结果平均成本降低 2.5%」这样的经历。
- 情境绑定:时间、地点、参与者、市场环境
- 叙事完整性:起因、经过、结果形成完整故事
- 反思标注:事后的经验教训和模式总结
情景记忆可以进一步区分为两类:
实体记忆:追踪实体的身份一致性。
- 「Apple = AAPL = 那家做 iPhone 的公司」
- 「张先生 = 客户 C001 = 风险偏好 R2 的退休教师」
实体记忆确保智能体在不同语境下识别同一对象。当用户说「那家科技巨头」时,智能体能关联到之前讨论过的苹果公司。
事件记忆:记录时序序列和因果链条。
- 「分析苹果财报 → 识别增长放缓信号 → 推荐谨慎持有 → 客户减仓 20%」
- 「美联储加息 → 科技股承压 → 调低估值目标」
事件记忆是决策复盘和经验迁移的基础。
6.5.2 决策轨迹记录
决策日志是情景记忆的核心载体。它建立「决策-结果」的映射关系,支持事后复盘与反思学习。
一条典型的投资决策情景记忆结构如下:
# 情景记忆示例
episode_id: EP_2024_08_15_001
timestamp: 2024-08-15T14:30:00+08:00
participants: [客户张先生, 投资顾问智能体]
market_context:
regime: 牛市末期
signals: [科技股当日涨8%, 成交量放大150%, 市场情绪亢奋]
narrative:
trigger: 客户要求以市价买入某科技股
analysis:
- 识别风险:股价短期涨幅过大,追高风险高
- 历史参照:类似情况下次日回调概率 65%
- 备选方案:[市价买入, 分批建仓, 等待回调]
decision: 建议客户等待回调,分三批建仓
outcome:
result: 客户采纳建议
metrics:
- 次日股价回调 3%
- 分三批建仓完成
- 平均成本比市价买入降低 2.5%
reflection:
pattern: 短期急涨 + 情绪亢奋 → 高概率回调
strategy_validated: 分批建仓在追涨场景有效
applicable_conditions: 适用于非趋势性的短期急涨
lessons: 情绪指标是追高场景的关键预警信号这种结构化的记录方式,让智能体能够:
- 回顾决策的完整逻辑链条
- 验证策略的实际效果
- 提炼可复用的经验模式
决策日志应该记录「为什么」而不仅仅是「做了什么」。记录「在市场过热信号下建议减仓科技股」比单纯记录「减仓科技股 10%」更有学习价值。
市场情境标签是情景记忆的重要组成部分。通过标记当时的市场状态(牛市、熊市、盘整、危机),智能体可以在未来回答「相似情境下什么策略有效」这类问题。
| 情境标签 | 典型特征 | 历史案例 |
|---|---|---|
| 牛市 | 指数持续上涨,情绪乐观 | 2019-2021 科技股行情 |
| 熊市 | 指数持续下跌,恐慌情绪 | 2022 年加息周期 |
| 盘整 | 窄幅震荡,方向不明 | 2024 Q2 市场 |
| 危机 | 急跌、流动性紧张 | 2020 年 3 月新冠冲击 |
6.5.3 元认知模式与认知演化
情景记忆的更高级应用是支持智能体的「元认知」能力——不仅记住做了什么,还要理解自己是如何思考问题的。
从「知道什么」到「如何思考」
人类学习新领域时,获得的不只是知识累积,更是认知方式的转变。学习 Angrist 的计量经济学方法后,你看问题的方式会改变:
| 学习前 | 学习后 |
|---|---|
| 看到相关性就下结论 | 先问「因果识别策略是什么?」 |
| 相信模型预测 | 追问「理想实验是什么样的?」 |
| 追求一般性证明 | 承认 LATE 的局部性 |
这些不是具体知识,而是可迁移的认知工具。智能体也应该记录和积累这类元认知模式。
认知演化的三个层次:
层次 1:记住事实和数据
↓
层次 2:记住推理模式和判断框架
↓
层次 3:记住「什么时候用什么思考方式」元认知(Metacognition)是「关于认知的认知」——对自己思维过程的觉察和调控。一个具有元认知能力的智能体,不仅能分析问题,还能反思自己的分析方法是否恰当。
在记忆架构设计中,可以将元认知模式作为独立层级存在:
Layer 0: 基础模型能力
↓
Layer 1: 核心身份(价值观、决策风格)
↓
Layer 1.5: 元认知模式 [关键层]
- 问题处理框架
- 评估想法的通用流程
- 变化频率:每学习一个新领域后
↓
Layer 2: 领域知识
↓
Layer 3: 会话上下文Layer 1.5 存储的是「如何思考」的模式,而非「知道什么」的知识。这些模式一旦习得,可以迁移应用到新的领域。
金融场景的元认知模式示例:
## 元认知模式:估值分析框架
### 触发条件
当需要评估一家公司是否被高估或低估时
### 思考步骤
1. 首先确定估值基准(行业平均、历史均值、可比公司)
2. 选择合适的估值指标(PE、PB、PS、EV/EBITDA)
3. 分析估值差异的原因(增长预期、风险溢价、流动性)
4. 判断估值差异是否合理
### 常见陷阱
- 忽略行业差异,直接横向比较
- 使用单一指标下结论
- 混淆市值与企业价值
### 来源
2024 年分析 50 家科技公司后总结6.5.4 经验迁移与类比推理
情景记忆的一个重要应用是支持类比推理。当智能体面对新的市场情境时,可以检索历史上的相似情况,借鉴过往经验。
在投资领域,有一句名言:「历史不会重演,但会押韵。」2022-2023 年的美联储加息周期与 1994-1995 年有诸多相似之处,了解历史能帮助我们更好地应对当下。
市场情景回顾
当前市场出现「美联储暂停加息 + 经济软着陆信号 + 科技股低估值」的组合时,智能体可以检索 1995-1996 年的类似情况,分析当时市场的后续走势。
客户行为模式
首次经历熊市的投资者往往高估自己的风险承受能力。智能体记录客户在市场下跌时的真实反应(频繁查看账户、焦虑情绪、考虑赎回),用于校正风险画像。
跨智能体经验迁移
在多智能体系统中,情景记忆支持追踪「哪个智能体做了什么决策」。研究智能体的分析经验可以迁移给执行智能体,避免重复劳动。
6.6 Agentic RAG:智能检索增强
金融分析师需要回答这个问题:「苹果公司 2024 年相比 2023 年盈利能力是否改善?」
如果只是机械地搜索一次,可能只找到 2024 年的数据。但经验丰富的分析师会这样做:先检索 2024 年财报,提取净利润率;再检索 2023 年财报,提取同一指标;然后计算变化;如果发现数据异常,还会交叉验证。
这种主动规划、动态调整、自我验证的检索方式,就是 Agentic RAG 的核心理念。
6.6.1 从被动检索到主动决策
传统的检索增强生成(RAG)就像一个听话但不会变通的图书管理员——你问什么,他就去找什么,找到什么给你什么,不会思考这些资料是否真的有用。
Agentic RAG 是赋予检索增强生成系统智能体能力的技术范式。它让 RAG 系统从被动的「检索-生成」流程,进化为主动规划、动态调整、自我反思的智能检索助手。核心转变是:检索是「决策」而非「步骤」。
传统 RAG 与 Agentic RAG 的对比:
| 特性 | 传统 RAG | Agentic RAG |
|---|---|---|
| 检索流程 | 固定(检索一次 → 生成) | 动态(可多轮检索、调整策略) |
| 信息需求判断 | 无(总是检索) | 有(判断是否需要检索) |
| 检索质量评估 | 无 | 评估相关性,必要时重新检索 |
| 多源协调 | 单一检索源 | 可调用多种工具(向量库、SQL、API) |
| 答案验证 | 无 | 自我反思,交叉验证 |
6.6.2 四大核心能力
Agentic RAG 具备四大核心能力,它们相互配合,形成完整的智能检索闭环。
1. 规划(Planning)
面对复杂问题,智能体会先分解任务,规划检索路径。
用户问题:对比苹果和三星 2024 年盈利能力
规划结果:
步骤 1:检索苹果 2024 年财报,提取净利润和营收
步骤 2:检索三星 2024 年财报,提取净利润和营收
步骤 3:计算两家公司的净利润率
步骤 4:对比分析,得出结论2. 检索驱动推理(Retrieval-driven Reasoning)
智能体基于检索结果动态调整推理路径,而不是机械执行预设流程。
执行步骤 1:检索到苹果营收 3890 亿美元
发现问题:只有营收,没有成本数据,无法计算净利润
动态调整:补充检索「苹果 2024 年净利润」或「苹果 2024 年利润表」
继续执行:获取净利润 967 亿美元,计算净利润率 24.9%3. 工具使用(Tool Use)
智能体根据任务特点选择合适的工具,而不是只依赖单一检索方式。
| 信息类型 | 推荐工具 | 示例 |
|---|---|---|
| 财报数据 | 向量检索 | 检索年报 PDF 中的财务数据 |
| 结构化数据 | SQL 查询 | 查询数据库中的股价、估值指标 |
| 实时信息 | API 调用 | 获取最新股价、汇率 |
| 最新动态 | 网络搜索 | 搜索公司新闻、政策变化 |
4. 自我反思(Self-Reflection)
智能体会评估检索和生成的质量,发现问题及时纠正。
生成答案:「苹果 2024 年营收增长 15%」
自我反思:这个增速异常高,需要验证
重新检索:查找官方财报原文
发现错误:实际增速是 2.1%,之前检索到的是分析师预测
纠正答案:「苹果 2024 年营收实际增长 2.1%」6.6.3 关键设计模式
Agentic RAG 有四种关键设计模式,适用于不同场景。
Self-RAG:反射标记系统
Self-RAG 的核心是在生成过程中插入反射标记,指导每一步决策。
| 反射标记 | 含义 | 选项 |
|---|---|---|
| [Retrieve] | 需要检索吗? | yes / no / continue |
| [IsRelevant] | 文档相关吗? | relevant / irrelevant |
| [IsSupported] | 文档支持答案吗? | fully / partially / no support |
这种机制让智能体能够:
- 避免不必要的检索(当模型已有足够知识时,标记 [Retrieve: no])
- 过滤不相关的文档(标记 [IsRelevant: irrelevant] 后跳过)
- 验证答案的可靠性(只采用 [IsSupported: fully] 的内容)
金融场景示例:
用户询问:「苹果 2024 Q3 净利润是多少?」
智能体内部决策:
[Retrieve: yes] 需要检索财报数据
↓ 检索到文档
[IsRelevant: relevant] 文档是 2024 Q3 财报,相关
↓ 提取信息
[IsSupported: fully] 文档明确列出净利润 $22.9B
↓ 生成答案
「苹果 2024 Q3 净利润为 229 亿美元」CRAG:检索质量分级
CRAG(Corrective RAG)根据检索质量动态调整策略。
检索结果质量评估:
├── Correct(高相关)→ 直接使用
├── Ambiguous(部分相关)→ 补充检索 + 信息融合
└── Incorrect(不相关)→ 丢弃,尝试外部搜索Multi-Hop RAG:多文档跳跃
很多复杂问题无法通过一次检索解决,需要在多个文档之间「跳跃」,建立逻辑链条。
问题:比亚迪 2024 年 Q3 毛利率比 Q2 提高了还是降低了?
第 1 跳:检索 2024 Q3 财报 → 毛利率 21.9%
第 2 跳:检索 2024 Q2 财报 → 毛利率 20.7%
第 3 跳:对比分析 → Q3 比 Q2 提高 1.2 个百分点
第 4 跳(可选):检索原因 → 规模效应、成本优化Adaptive RAG:策略分级
根据问题复杂度自动选择策略。
| 问题类型 | 检索策略 | 示例 |
|---|---|---|
| 简单事实 | 单次检索或直接回答 | 「苹果的股票代码是什么?」 |
| 对比分析 | Multi-Hop | 「A 公司和 B 公司谁盈利能力更强?」 |
| 因果推理 | Self-RAG + 验证 | 「股价下跌的原因是什么?」 |
- Multi-Hop RAG:适合跨期对比、跨公司对比、因果分析
- Self-RAG:适合需要高准确性的场景(金融分析、合规审查)
- Adaptive RAG:适合问题复杂度差异大的综合问答系统
6.6.4 GraphRAG vs Vector RAG
向量检索是 RAG 的基础方式,但它有一个根本局限:丢失关系结构。
Vector RAG 的局限
向量数据库可以回答「苹果 Q3 营收是多少?」——因为这是独立事实检索。但它很难回答「苹果的哪些供应商也报告了营收增长?」——因为供应商关系没有编码在向量空间中。
| 特性 | Vector RAG | GraphRAG |
|---|---|---|
| 准确率 | ~60-70% | ~75-85% |
| 关系结构 | 丢失 | 保留 |
| 幻觉率 | 较高 | 降低约 30% |
| 适用查询 | 独立事实检索 | 关系推理、因果分析 |
GraphRAG 的优势
GraphRAG 通过提取实体和关系,构建知识图谱,支持关系推理。
知识图谱片段:
[苹果公司] --供应商--> [台积电]
[苹果公司] --供应商--> [富士康]
[台积电] --竞争对手--> [三星电子]
可回答的问题:
- 苹果的供应商有哪些?
- 苹果和三星有共同供应商吗?
- 供应商中谁的营收增长最快?实证数据(来源:Deep Memory Retrieval Benchmark, 2024)
深度记忆检索(DMR)基准测试显示:
| 系统 | 准确率 | 关键特点 |
|---|---|---|
| Zep(时序知识图谱) | 94.8% | 最佳准确率,保留时间有效性 |
| MemGPT | 93.4% | 综合表现良好 |
| GraphRAG | 75-85% | 关系结构保留,20-35% 准确率提升 |
| Vector RAG | 60-70% | 丢失关系结构 |
| 递归摘要 | 35.3% | 严重信息损失 |
递归摘要(看似「渐进式总结」的默认方法)仅有 35.3% 的准确率。这意味着简单的对话压缩可能丢失大量关键信息。选择压缩策略时要谨慎。
选择建议
| 场景 | 推荐方案 |
|---|---|
| 独立事实查询 | Vector RAG |
| 关系推理、因果分析 | GraphRAG |
| 时间敏感查询(「当时知道什么」) | 时序知识图谱 |
| 成本敏感场景 | Vector RAG + 元数据过滤 |
6.6.5 记忆整合
长期运行的智能体需要定期整合记忆,保持系统健康。记忆整合(Memory Consolidation)是维护记忆质量的关键机制。
触发条件
记忆整合应在以下情况触发:
- 记忆数量超过阈值(如 10,000 条)
- 检索返回过多过时结果
- 定期调度(如每周一次)
整合流程
记忆整合流程:
1. 识别重复
- 语义相似度 > 0.95 的记忆合并
- 保留最新版本
2. 合并相关
- 同一实体的多条记忆整合
- 保留时间线完整性
3. 更新有效性
- 检查时间戳,标记过时信息
- 更新 valid_until 字段
4. 归档过时
- 超过保留期的记忆移至归档
- 保留审计痕迹金融场景示例
# 整合前
- 记忆 1:「张先生风险偏好为激进型」(2023-01)
- 记忆 2:「张先生风险偏好为稳健型」(2024-06)
- 记忆 3:「张先生经历熊市后变得谨慎」(2024-06)
# 整合后
- 张先生风险偏好:
- 2023-01 至 2024-05: 激进型
- 2024-06 至今: 稳健型
- 变化原因: 熊市经历6.7 Claude Code 记忆管理实践
使用 Claude Code 开发金融分析项目时,一个常见的痛点是:每次开启新会话都要从零开始建立上下文。你不得不重复告诉 Claude 项目是什么、偏好是什么、数据规范是什么。
Claude Code 的记忆系统正是为解决这个问题而设计。它让智能体能够记住项目规范、个人偏好和工作习惯,从「健忘者」变成「知识伙伴」。
6.7.1 CLAUDE.md 文件体系
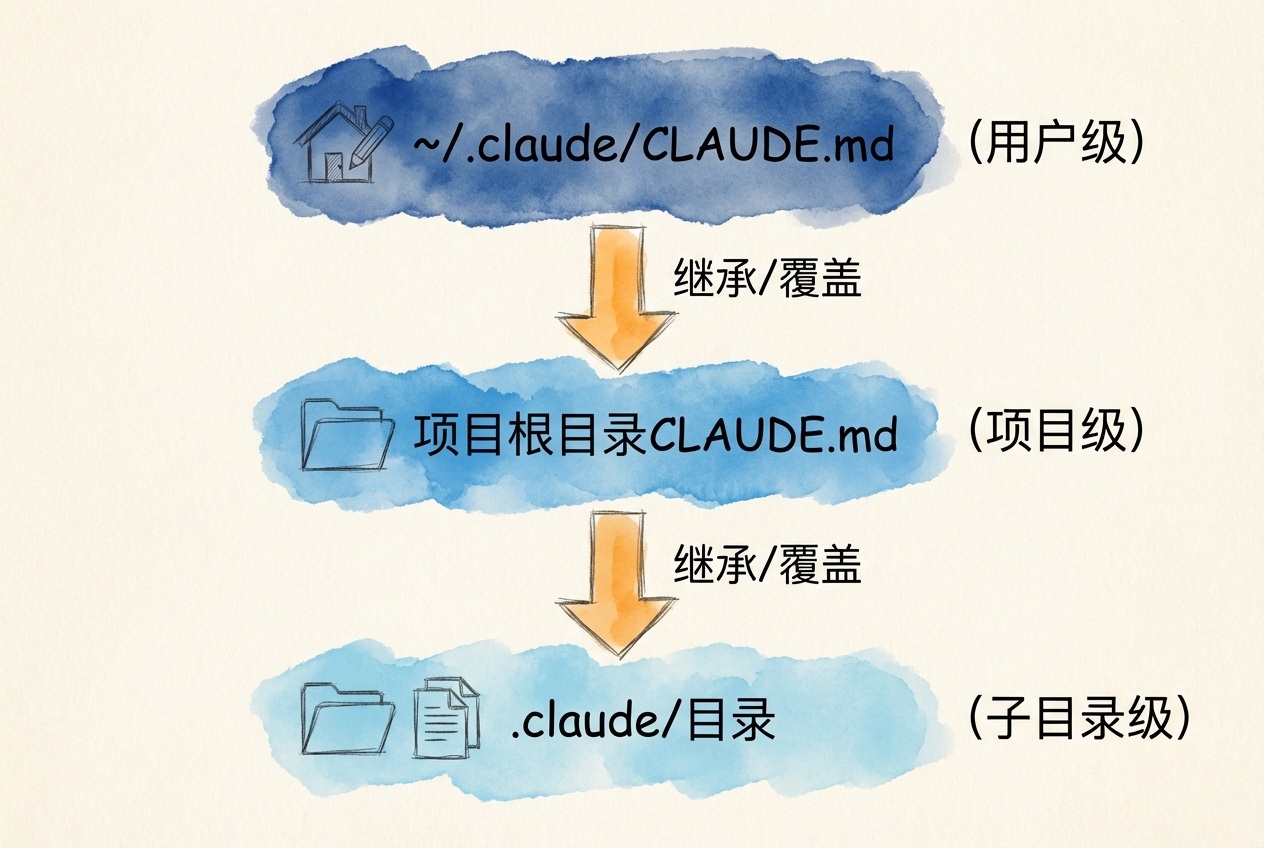
CLAUDE.md 是 Claude Code 的「长期记忆中枢」。它采用分层设计,让你既能定义全局偏好,又能针对特定项目设置规范。
三种记忆位置
| 记忆类型 | 文件位置 | 作用范围 | 典型用途 |
|---|---|---|---|
| 用户记忆 | ~/.claude/CLAUDE.md |
所有项目 | 个人偏好、通用规范 |
| 项目记忆 | ./CLAUDE.md |
当前项目(团队共享) | 项目架构、编码规范 |
| 子模块记忆 | ./subdir/CLAUDE.md |
子目录 | 模块特定约定 |
加载机制
Claude Code 启动时会递归查找 CLAUDE.md 文件:
- 从当前工作目录开始
- 向上逐级查找直到用户主目录
- 层层叠加,形成完整上下文
CLAUDE.md 本质上是系统提示(System Prompt)——它定义了智能体在这个项目中应该如何行事。因此,CLAUDE.md 永远不会被压缩。即使执行 /compact,CLAUDE.md 的内容也会完整保留。
导入功能
使用 @path/to/file 语法可以导入其他文件的内容:
# CLAUDE.md
## 项目概述
这是一个金融数据分析平台。
## 配置导入
@config/coding_standards.md
@config/data_sources.md
@config/compliance_rules.md导入功能支持相对路径和绝对路径,最大递归深度为 5 层。
6.7.2 会话状态管理命令
Claude Code 提供几个核心命令管理会话状态。理解它们的语义有助于选择正确的策略。
命令语义映射
| 命令 | 对应策略 | 语义 | 适用场景 |
|---|---|---|---|
/clear |
分区 | 会话级分区,完全清空历史 | 开始全新任务 |
/compact |
压缩 | 保留核心信息,释放空间 | 继续当前任务,上下文过长 |
/compact 指令 |
选择性压缩 | 按指令保留特定信息 | 需要精确控制保留内容 |
/memory |
编辑 | 打开并编辑 CLAUDE.md | 更新项目规范 |
--resume |
恢复 | 恢复之前的会话 | 跨天继续工作 |
--continue |
继续 | 继续最近的会话 | 昨天的工作今天继续 |
/clear 命令
/clear完全清空当前对话历史。这是「会话级分区」——相当于开启一个全新的工作空间。
适用于: - 开始完全不相关的新任务 - 切换到不同项目 - 对话上下文已混乱,需要重新开始
/clear 对当前会话是破坏性的,但 CLAUDE.md 文件内容会保留。如果想返回旧会话,应使用 --resume 命令。
/compact 命令
/compact将当前对话压缩为更短的摘要,保留重要事实和决策。
更强大的用法是带指令压缩:
/compact 仅保留决策和待办事项
/compact 保留所有关于估值模型的讨论
/compact 保留客户的风险偏好和投资目标这让你能精确控制保留什么信息,而不是完全依赖自动判断。
把 /compact 想象成会议纪要。一场两小时的会议,纪要可能只有两页。纪要保留了关键决策和行动项,但省略了具体讨论过程。
6.7.3 三层信息架构实践
高效的记忆管理需要区分不同类型信息的加载策略。三层信息架构(L1/L2/L3)是一种经过验证的模式。

架构设计
| 层级 | 何时加载 | 内容类型 | Token 成本 |
|---|---|---|---|
| L1 | 始终 | SKILL.md 元数据、核心约束 | ~50 tokens |
| L2 | 按需 | MODULE.md 指令、API 规范 | ~60-80 tokens |
| L3 | 即时 | .jsonl/.yaml 具体数据 | 可变 |
L1 层(元数据):始终加载
# L1: 项目元数据(始终加载)
项目: 金融分析系统
技术: Python 3.10+, yfinance
约束: 输出 JSON 格式
核心规范: @config/core_rules.md这些是智能体必须知道的基本信息,无论执行什么任务都需要。
L2 层(指令):按需加载
# L2: 按需加载(在 CLAUDE.md 中引用,任务相关时加载)
@config/api_specs.md # API 开发任务时加载
@config/data_processing.md # 数据处理任务时加载
@config/reporting_format.md # 报告生成任务时加载这些是特定任务需要的详细指令,不需要时不加载。
触发机制:「任务相关时加载」的判断逻辑包括: - 关键词匹配:用户请求中包含「API」「接口」时加载 api_specs.md - 模块调用:执行数据处理函数时加载 data_processing.md - 显式引用:用户直接要求「按照报告格式」时加载 reporting_format.md
L3 层(数据):即时加载
# L3: 即时加载(在任务中明确引用时才加载)
@data/client_profiles.jsonl # 分析特定客户时加载
@data/market_events.yaml # 分析市场事件时加载这些是具体的数据文件,只在明确需要时加载。
Token 效率
采用三层架构后: - 优化后:~650 tokens/任务 - 未优化:~5000 tokens/任务 - 节省:约 87%
计算示例:
假设一个典型金融分析任务:
| 层级 | 内容 | 优化前 | 优化后 |
|---|---|---|---|
| L1 元数据 | 项目名称、技术栈 | 50 | 50 |
| L2 指令 | 全部指令一次性加载 | 800 | 80(按需) |
| L3 数据 | 全部数据一次性加载 | 4000 | 500(即时) |
| 冗余信息 | 未清理的历史 | 150 | 20 |
| 合计 | 5000 | 650 |
节省率 = (5000 - 650) / 5000 = 87%
三层架构的核心思想是「渐进式加载」——先加载最少必要信息,需要更多细节时再按需获取。这与金融领域的「按需配置」原则一致:不要一次性配置所有资产,而是根据需求逐步建仓。
6.7.4 上下文管理最佳实践
主动压缩策略
不要等到系统自动触发压缩才处理。建议采用主动压缩策略:
| 利用率 | 状态 | 建议操作 |
|---|---|---|
| 70% | 预警 | 开始考虑压缩 |
| 80% | 触发 | 执行 /compact |
| 90% | 紧急 | 立即 /compact 或 /clear |
实践建议:每 30-50 轮对话后主动执行 /compact,主动管理上下文是高效使用智能体的关键技能。
CLAUDE.md 管理规范
| 规范 | 原因 |
|---|---|
| 保持在 200 行以内 | 过长会占用过多上下文窗口 |
| 使用 @import 分离配置 | 保持主文件简洁,便于维护 |
| 核心信息写进去,详细信息通过路径引用 | CLAUDE.md 是「门户」而非「仓库」 |
| 定期更新,删除过时内容 | 过时信息可能误导智能体 |
观察遮蔽在实践中的应用
研究发现,工具输出占据了典型工作流中 83.9% 的 tokens。这是优化的最大杠杆点。
Claude Code 的 /compact 命令实际上实现了「观察遮蔽」策略:
观察遮蔽策略:
固定遮蔽:「前 X 行已省略」
- 研究发现:固定遮蔽可匹配 LLM 摘要的效果
- 优势:零 token 开销(vs 摘要的 5-7% 开销)
适用场景:
- 长日志输出
- 重复格式的数据
- 已处理完成的中间结果问题:Claude 似乎没有读取 CLAUDE.md 的内容
可能原因和解决方法: 1. 文件位置错误——确保在项目根目录或当前工作目录 2. 文件名拼写错误——必须是 CLAUDE.md(大写) 3. 导入路径错误——检查 @path/to/file 路径是否正确 4. 文件过大——控制在 200 行以内,过长会影响加载
问题:会话恢复失败
可能原因和解决方法: 1. 会话已过期——Claude Code 会话有保留期限 2. 会话 ID 错误——使用 claude --resume 交互式选择 3. 权限问题——检查会话存储目录权限
6.7.5 实践示例:金融分析项目配置
以下是一个金融分析项目的完整记忆架构示例。
项目目录结构
finance-analysis/
├── CLAUDE.md # 项目级记忆(L1)
├── config/
│ ├── data_sources.md # 数据源配置(L2)
│ ├── coding_standards.md # 代码规范(L2)
│ └── compliance_rules.md # 合规要求(L2)
├── data/
│ ├── client_profiles.jsonl # 客户画像数据(L3)
│ └── market_events.yaml # 市场事件记录(L3)
├── WORKING_PLAN.md # 工作计划(动态更新)
└── REMEMBER.md # 经验教训(持续积累)CLAUDE.md 示例
# 金融分析系统
## 项目概述
为理财顾问提供客户画像分析和投资建议工具。
## 技术栈
- Python 3.11 + Pandas + NumPy
- 数据源:Wind API、同花顺接口
- 存储:SQLite(开发)/ PostgreSQL(生产)
## 核心约束
- 所有金额单位:人民币元
- 日期格式:YYYY-MM-DD
- 收益率保留 2 位小数
## 按需配置
@config/data_sources.md
@config/coding_standards.md
@config/compliance_rules.md
## 工作状态
@WORKING_PLAN.md
## 经验教训
@REMEMBER.mdREMEMBER.md 示例
## 常见错误
- 股票代码查询时,上交所用 .SS 后缀,深交所用 .SZ 后缀
- 日期范围查询时,注意中国节假日导致的数据缺失
- 处理财报数据前,先检查会计准则变更
## 最佳实践
- 每次 API 调用后检查返回状态码
- 大量数据处理使用分页,避免内存溢出
- 敏感数据(客户身份证号)必须脱敏处理
## 技术决策记录
### 2026-01-25:风险评估模型选型
- 决策:采用问卷 + 行为分析双轨制
- 原因:单一问卷无法反映真实风险承受能力
- 参考:客户在 2024 年熊市中的实际行为数据通过这套机制,Claude Code 真正成为了「记得住」的智能助手——不仅记得当前对话,还记得整个项目的背景、规范和历史经验。
本节小结
| 章节 | 核心概念 | 实践要点 |
|---|---|---|
| 6.5 | 情景记忆 | 记录决策轨迹,支持元认知演化 |
| 6.6 | Agentic RAG | 四大能力 + 四种模式,GraphRAG 提升关系推理 |
| 6.7 | Claude Code 实践 | 三层信息架构,主动压缩策略 |
6.8 最佳实践:上下文工程四策略
上下文窗口是具有机会成本的经济资源。与其被动应对窗口耗尽,不如建立主动防御体系。本节介绍四种递进策略,从预防到应急,构建完整的上下文管理方案。
6.8.1 四策略框架概述
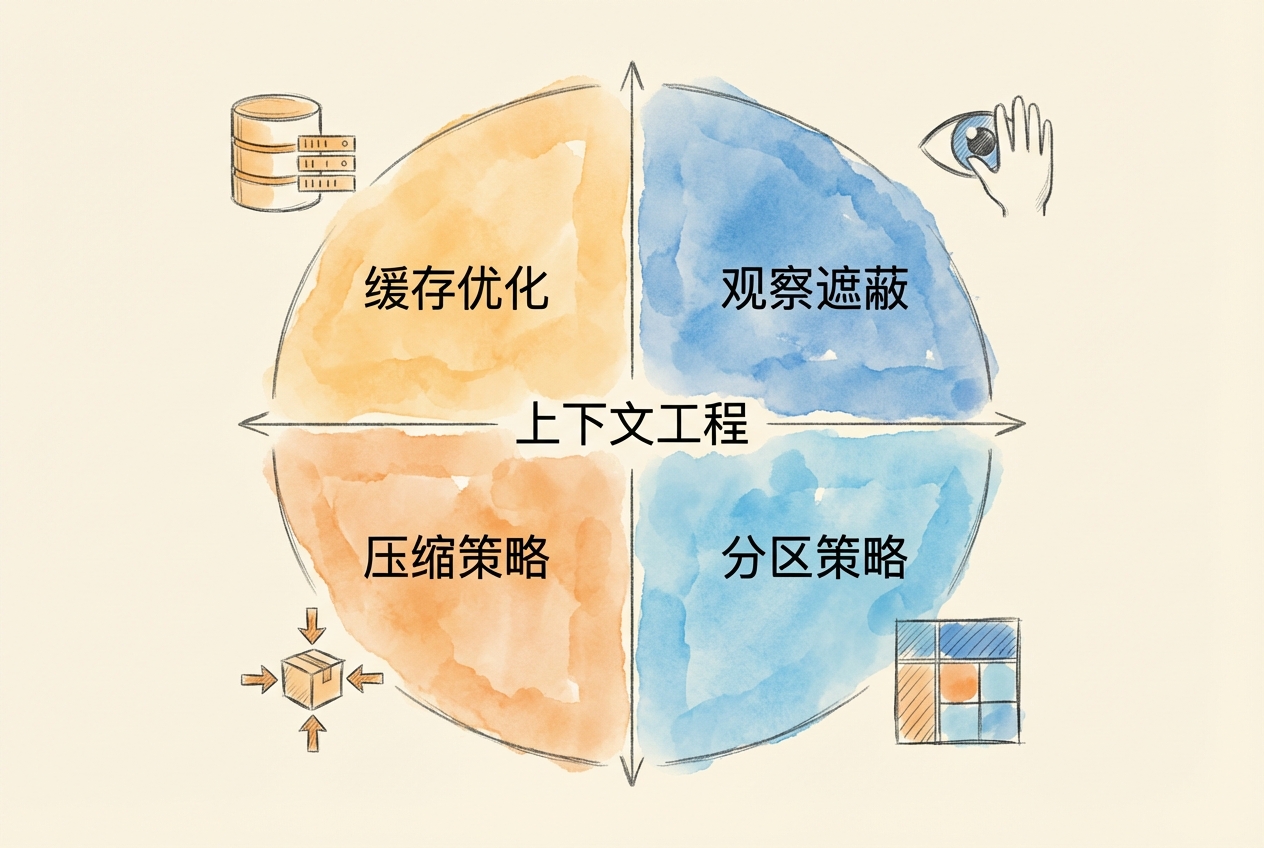
四种策略形成层层防御:
策略 1: 缓存优化(预防)
↓ 最大化缓存命中,10 倍成本差异
↓ 设计缓存友好的提示结构
策略 2: 观察遮蔽(早期干预)
↓ 工具输出 = 83.9% tokens,最大杠杆
↓ 固定遮蔽可匹配 LLM 摘要效果
策略 3: 压缩策略(主动管理)
↓ 70-80% 利用率时触发
↓ 结构化摘要保留信号,丢弃噪音
策略 4: 分区策略(架构解决方案)
↓ 子智能体隔离上下文
↓ 文件交接策略,避免信息传递损耗选择策略的决策框架:
| 上下文状态 | 首选策略 | 理由 |
|---|---|---|
| 利用率 < 50% | 缓存优化 | 预防胜于治疗 |
| 工具输出占比 > 50% | 观察遮蔽 | 瞄准最大消耗源 |
| 利用率 70-80% | 压缩策略 | 主动释放空间 |
| 任务可拆分 | 分区策略 | 从架构层面解决 |
不要等到上下文耗尽才行动。研究表明,在 70-80% 利用率时主动优化,比等到质量下降信号再处理,效果好得多。
6.8.2 缓存优化:10 倍成本差异
API 服务商对缓存命中的输入 token 提供大幅折扣。以 Claude Sonnet 4 为例:
| Token 类型 | 成本 |
|---|---|
| 未缓存输入 | $3.00/MTok |
| 缓存输入 | $0.30/MTok |
| 差异 | 10 倍 |
这意味着设计「缓存友好」的提示结构能带来显著成本节省。
缓存友好的内容排序原则:
[稳定内容优先] ← 可缓存(系统提示、工具定义)
[常用模板次之] ← 部分可缓存(格式要求、常用指令)
[动态内容最后] ← 无法缓存(当前查询、实时数据)什么会破坏缓存:
- 在系统提示中加入时间戳(每次请求都不同)
- 格式不一致(同一类请求结构不同)
- 频繁调整系统提示措辞
金融应用示例:
假设你的金融分析系统有 4 万 tokens 的稳定前缀(系统提示 + 工具定义 + 分析框架)。每天处理 100 个请求:
无缓存成本:40,000 × 100 × $3/MTok = $12/天 = $360/月
缓存命中成本:40,000 × 100 × $0.3/MTok = $1.2/天 = $36/月
月节省 = $360 - $36 = $324(90%)把 CLAUDE.md 想象成「固定资产」——它的内容应该稳定,不要频繁修改。稳定的系统提示是缓存优化的基础。
6.8.3 观察遮蔽:零开销的高杠杆策略
研究发现,在典型的智能体工作流中,工具输出占据 83.9% 的 tokens。这是优化的最大杠杆点。
观察遮蔽(Observation Masking) 的核心思想是:工具输出在使用后往往不再需要完整保留。可以用简短的占位符替换冗长的原始输出。
原始工具输出(2000 tokens):
{
"date": "2026-01-27",
"results": [
{"symbol": "AAPL", "price": 185.23, "volume": 52341000, ...},
{"symbol": "MSFT", "price": 412.56, "volume": 28765000, ...},
... 更多数据 ...
]
}
遮蔽后(50 tokens):
[工具输出已处理:获取了 10 只股票的实时行情数据,已提取关键指标]关键发现:
研究表明,固定遮蔽(如「前 X 行已省略」)的效果可以匹配甚至超过 LLM 生成的摘要,同时带来零 token 开销(LLM 摘要通常消耗 5-7% 额外 tokens)。
遮蔽策略选择:
| 内容类型 | 策略 | 理由 |
|---|---|---|
| 最近一轮工具输出 | 保留完整 | 当前任务可能需要 |
| 3 轮以上的工具输出 | 选择性遮蔽 | 提取关键点,隐藏细节 |
| 重复格式的数据 | 立即遮蔽 | 格式已知,只需保留结论 |
| 已完成处理的中间结果 | 完全遮蔽 | 任务已完成,不再需要 |
6.8.4 压缩策略:结构化摘要
当上下文利用率达到 70-80% 时,应主动触发压缩。但压缩有代价——研究显示,递归摘要(看似「渐进式总结」的默认方法)会丢失 65% 的准确率。
压缩的代价——DMR 基准测试数据:
| 压缩方法 | 准确率 | 关键洞见 |
|---|---|---|
| 时序知识图谱(Zep) | 94.8% | 时间有效性是关键 |
| MemGPT | 93.4% | 综合表现良好 |
| GraphRAG | 75-85% | 保留关系结构 |
| Vector RAG | 60-70% | 丢失关系结构 |
| 递归摘要 | 35.3% | 严重信息损失 |
结构化摘要模板:
与其让模型自由摘要,不如提供结构化模板,强制保留关键信息:
## 会话意图
[用户的核心目标]
## 已修改文件
- file1: 变更内容
- file2: 变更内容
## 已做决策
- 决策 1: 理由
- 决策 2: 理由
## 当前状态
[任务进度:完成/进行中/待开始]
## 下一步
1. 具体步骤 1
2. 具体步骤 2Claude Code 中的实践:
# 带指令的定向压缩
/compact 仅保留决策、待办事项和配置更改
# 保留特定主题
/compact 保留所有关于估值模型的讨论文件追踪信息特别容易在压缩中丢失。即使使用最佳压缩方法,文件追踪评分也只有 2.2-2.5/5.0。关键文件操作应写入 CLAUDE.md,而非仅依赖会话记忆。
6.8.5 分区策略:子智能体隔离上下文
最彻底的优化是从架构层面解决——将复杂任务拆分给子智能体,每个子智能体有独立的上下文空间。
子智能体的本质是上下文隔离,而非拟人化分工。
主智能体上下文:
┌──────────────────────────────────────┐
│ 系统提示 + 用户需求 + 任务规划 │
│ 容量:约 20K tokens │
└──────────────────────────────────────┘
↓ 分派任务
┌─────┴─────┐
↓ ↓
┌────────┐ ┌────────┐
│子智能体A│ │子智能体B│
│独立上下文│ │独立上下文│
│处理任务A│ │处理任务B│
└────────┘ └────────┘
↓ ↓
└─────┬─────┘
↓ 只返回摘要
┌──────────────────────────────────────┐
│ 主智能体接收:任务 A 完成,任务 B 完成 │
│ 新增消耗:约 200 tokens │
└──────────────────────────────────────┘文件交接策略:
子智能体不应将完整结果返回给主智能体(这会填满主智能体的上下文),而应:
- 将详细结果直接写入文件
- 只向主智能体返回状态摘要
错误做法:
子智能体 → [完整分析报告 5000 tokens] → 主智能体
正确做法:
子智能体 → [写入 output/analysis.md]
子智能体 → [状态摘要 100 tokens] → 主智能体金融场景示例:
主智能体(理财顾问)需要生成市场分析报告:
主智能体上下文:
┌────────────────────────────────────┐
│ 客户需求:分析科技股投资价值 │
│ 任务规划:分派给研究子智能体 │
└────────────────────────────────────┘
↓ 分派任务
┌───────────┐
│研究子智能体│
│独立上下文 │
│分析 AAPL │
└───────────┘
↓ 写入文件
output/aapl_analysis.md
↓ 返回摘要
┌────────────────────────────────────┐
│ 主智能体接收: │
│ ✅ AAPL 分析完成,盈利能力优秀 │
│ 消耗:约 50 tokens │
└────────────────────────────────────┘如果子智能体将完整分析(3000 tokens)返回主智能体,会填满上下文。
避免「电话游戏」问题:
信息经过多个上下文传递会逐步降级。直接文件交接避免了这种损耗。
6.8.6 常见陷阱与避免方法
| 陷阱类型 | 具体表现 | 解决方案 |
|---|---|---|
| 暴力加载 | 「直接粘贴所有内容到上下文」 | 渐进式加载,按需检索 |
| 信息同质化 | 所有信息同等对待 | 区分必要复杂度与偶发复杂度 |
| 速度优化偏差 | 优化生成速度而非理解深度 | 关注输出质量,非延迟 |
| 跳过规划 | 直接执行,缺乏设计 | 研究-规划-实现三阶段 |
| 不主动压缩 | 频繁触发自动压缩 | 每 30-50 轮主动 /compact |
| CLAUDE.md 过大 | 文件超过 200 行 | 使用 @import 分离配置 |
| 敏感数据裸存 | 未加密存储客户信息 | 加密敏感字段,环境变量存密钥 |
如果发现智能体「健忘」——频繁遗忘早期讨论的关键点、重复之前犯过的错误,很可能是自动压缩时丢失了重要信息。解决方案:
- 关键决策立即写入 CLAUDE.md 或 REMEMBER.md
- 主动压缩时明确指定保留内容
- 使用文件而非会话记忆存储重要信息
6.9 综合案例:自我进化的 AI 副本
本节介绍一个真实的 AI-Native 笔记系统的记忆管理架构。这个系统从简单的「省事工具」逐步发展为具有五层记忆架构、可自我进化的 AI 副本。通过这个案例,你将看到本章所有概念如何在实践中协同工作。
6.9.1 案例背景:从静态快照到动态演化
当密集使用 Claude Code 时,一个看似简单的问题浮现:每次开启新会话,都要从零开始建立上下文。
表面上是效率问题——每次都要告诉 Claude 你是谁、在做什么研究、偏好是什么。深层来看,这暴露了一个根本矛盾:
大语言模型是无状态的,但人的工作是有状态的。
Claude 可以在单次对话中表现得极其聪明,但它不记得昨天讨论过什么,不知道上个月学了什么方法,也不知道正在进行的研究项目进展。每次会话都是全新的「初次见面」。
痛点的三个层次:
| 层次 | 痛点描述 | 对应设计 |
|---|---|---|
| 操作层 | 每次重复输入项目配置、文件路径、偏好设置 | CLAUDE.md 体系 |
| 知识层 | Claude 不知道我学过什么、研究过什么 | domain-expertise.md + 知识库 |
| 认知层 | Claude 不知道我如何思考问题、做决策 | Persona.md + 元认知模式 |
从工具到系统的转变:
最初的解决方案是典型的「工程师思维」:既然每次都要输入相同的信息,为什么不把它存成文件?于是有了最早的 CLAUDE.md。
但很快意识到,这不只是「省事」的问题。当把自己的研究方向、思维模式、偏好写成文件让 Claude 读取时,实际上是在构建一个外化的认知系统。Claude 读取这些文件后,它的行为模式会发生变化——它开始像「我」一样思考问题。
范式转变:从「用 AI 提高效率」转向「用 AI 延伸认知」。对于 AI 来说,记忆就是身份。
6.9.2 AI-Native 笔记系统记忆架构
传统笔记系统是「人写笔记 → 人读笔记」。AI-Native 设计是「人写笔记 → AI 读笔记 → AI 辅助人」。笔记系统成为 AI 的「记忆基础设施」。
文件夹结构作为记忆分区:
NewNote/
├── CLAUDE.md # 核心配置 - 定义智能体行为
├── 0_待整理/ # 收件箱 - 短期缓冲
├── 1_导航/ # 外部索引 - 长期记忆指针
├── 3_背景/ # 用户画像 - 核心身份记忆
│ └── Persona.md # 多维人格画像
├── 9_学习笔记/ # 学习记录 - 知识积累
├── 10_xai_assets/ # XAI 智能体资产 - 自进化记忆
│ ├── domain-expertise.md # 当前专业能力档案
│ ├── knowledge-index.md # 知识库导航索引
│ └── versions/ # 历史版本快照
├── 11_交互日志/ # 会话记录 - 情景记忆
└── 系统配置/
└── lessons_learned.md # 经验教训记录四层记忆的具体实现:
| 记忆层 | 实现机制 | 更新频率 | 典型内容 |
|---|---|---|---|
| 工作记忆 | CLAUDE.md + 上下文注入 | 每次会话 | 项目配置、当前任务 |
| 短期记忆 | 11_交互日志/ 自动记录 | 每次会话结束 | 会话摘要、使用工具 |
| 长期记忆 | Persona.md + domain-expertise.md | 月/年 | 身份画像、专业知识 |
| 情景记忆 | versions/ + 反思笔记 | 按需 | 决策轨迹、认知转变 |
索引-内容分离模式:
Claude 可以先读索引文件,快速扫描有什么内容,再决定读哪些具体文件:
索引层:
- 1_导航/CLAUDE.md → 外部资源总索引
- 10_xai_assets/knowledge-index.md → 知识库导航
内容层:
- 实际笔记文件分布在各文件夹
- 通过索引按需访问CLAUDE.md 应该是「门户」而非「仓库」。核心信息写进去,详细信息通过路径引用。这是 6.4 节「三层信息架构」的具体应用。
6.9.3 五层记忆分层设计
这个系统采用五层记忆架构,每层有不同的变化频率和加载策略:
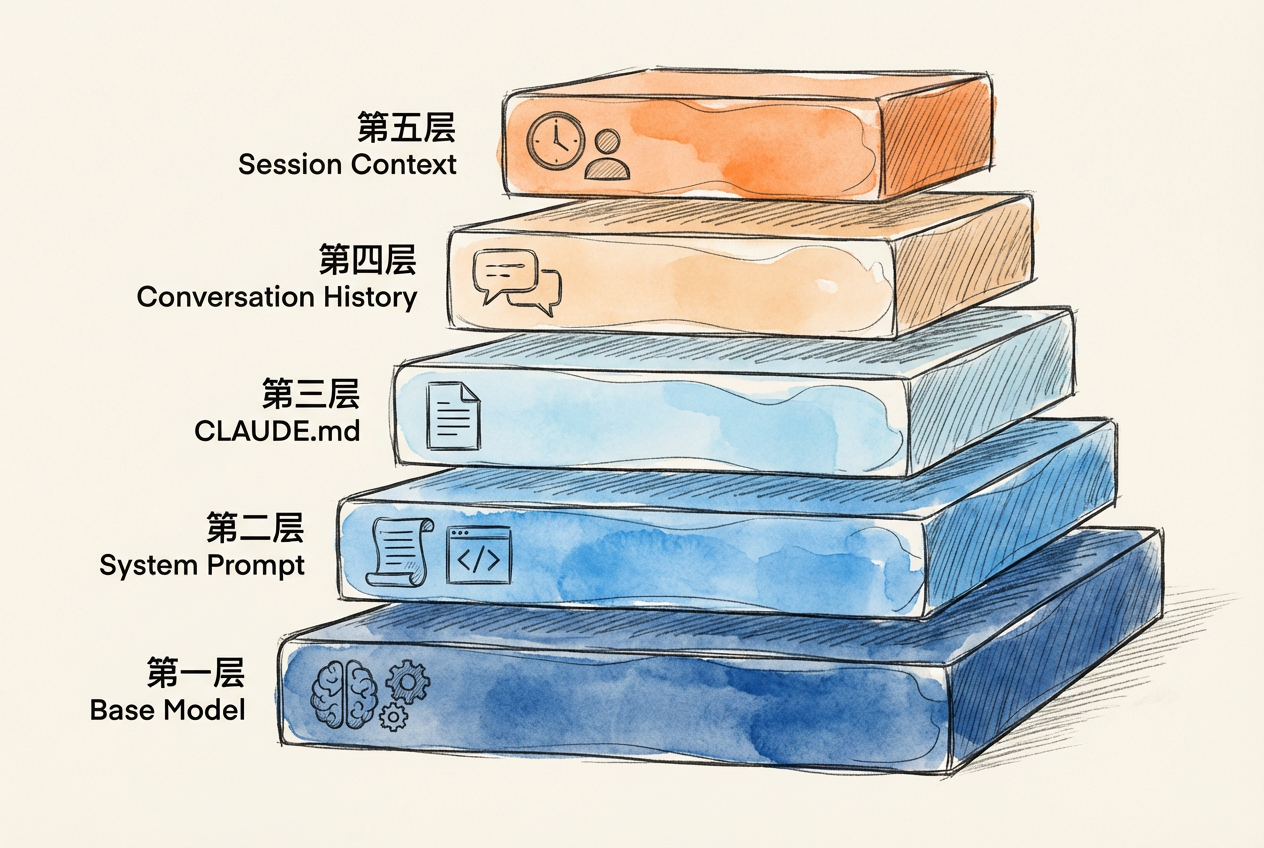
Layer 0: Anthropic Base Model (Claude)
↓
Layer 1: Core Identity(核心身份)
- 价值观、基本人格、道德边界
- 变化频率:年
↓
Layer 1.5: Meta-Cognitive Patterns(元认知模式)
- 问题处理框架、评估想法的通用流程
- 变化频率:每学习一个新领域后
↓
Layer 2: Domain Expertise Profile(专业知识档案)
- 专业知识的结构化摘要、研究项目状态
- 变化频率:每月合成
↓
Layer 3: Active Knowledge Retrieval(主动知识检索)
- 运行时从 vault 检索具体笔记、文献、数据
- 变化频率:实时
↓
Layer 4: Session Context(会话上下文)
- 当前对话的累积上下文、用户反馈和纠正
- 变化频率:每轮对话认知科学映射表:
| 系统层 | 认知记忆类型 | 变化频率 | 容量 |
|---|---|---|---|
| Persona | 语义记忆(自我概念) | 年 | 小 |
| 元认知 | 程序性记忆(思维技能) | 季 | 中 |
| 专业知识 | 语义记忆(领域知识) | 月 | 大 |
| 主动检索 | 情景记忆(具体事件) | 周 | 极大 |
| 会话上下文 | 工作记忆 | 分钟 | 有限 |
Persona 与 Domain Expertise 分离的原因:
| 维度 | Persona.md | domain-expertise.md |
|---|---|---|
| 描述 | 我是谁 | 我知道什么 |
| 内容 | 身份、价值观、风格 | 领域、深度、框架 |
| 变化 | 年 | 月/周 |
| 性质 | 相对稳定的认知特征 | 不断增长的知识资产 |
分离的好处:
- 更新独立:学了新东西只需更新 domain-expertise.md,不影响 Persona
- 加载灵活:有些任务只需要专业知识,不需要完整人格
- 演化清晰:可以单独追踪「知道什么」和「是谁」的变化轨迹
6.9.4 /xai-update:自动化专长更新
系统设计了专门的 Skill 来更新长期记忆。工作流分为四个阶段:
Phase 1: SCAN & ANALYZE(5-10 分钟)
类似年度考核中的「自我回顾」:回顾过去一年做了哪些项目,学到了什么新技能。
1. 读取当前 expertise profile
- 记录「Last Updated」日期
- 检查各领域当前深度级别
2. 扫描学习笔记库新增内容
- 检查 9_学习笔记/ 各文件夹修改日期
- 识别新增文件夹和笔记
3. 分析新内容深度
- 阅读文件夹的 _index.md
- 抽样 2-3 篇代表性笔记评估深度
- 识别新框架、深度变化、关键洞见
4. 起草更新建议Phase 2: VALIDATE(2-3 分钟)
类似晋升答辩前的「自我测试」:设计几个问题来检验自己是否真正掌握了新技能。
5. 生成验证问题
- 创建 3-5 个能区分深度级别的问题
- 示例:「解释平台包络策略,并举一个现实案例」
6. 对比旧版与新版的回答能力
- 旧档案能回答这些问题吗?
- 新档案能回答得更好/更完整吗?Phase 3: USER APPROVAL(交互式)
类似晋升评审的「主管确认」:将自我评估结果呈报上级审批,确保客观准确。
7. 呈现更新摘要
## Update Summary
**Proposed Changes**:
| Domain | Current → Proposed | Key Additions |
|--------|-------------------|---------------|
| Platform Econ | Intermediate → Adv Int | Envelopment |
8. 请求用户批准
- 选项:Approve / Show diff / Revise / CancelPhase 4: COMMIT(1-2 分钟)
类似 HR 系统的「档案更新」:正式记录能力变化,保留历史版本以备审计。
9. 备份旧版本
→ versions/domain-expertise_v{N}_{date}.md
10. 更新 domain-expertise.md
- 递增版本号
- 更新 Last Updated 日期
- 应用变更
11. 确认完成
✅ Update complete
- Backup saved: versions/domain-expertise_v3_20260127.md
- xai agent will use new profile on next invocation版本控制示例:
10_xai_assets/versions/
├── domain-expertise_v1_20260123.md
├── domain-expertise_v2_20260124.md
└── domain-expertise_v3_20260125.md| Date | Version | Key Changes |
|---|---|---|
| 2026-01-25 | v3 | Upgraded: Econometrics. Source: Train 14 chapters |
| 2026-01-24 | v2 | Added: Academic Writing. Source: Bellemare 8 chapters |
| 2026-01-23 | v1 | Initial profile |
成功标准:
一次好的更新应该:
- ✅ 反映真实学习(有 vault 笔记支撑)
- ✅ 提升 xai 回答领域问题的能力
- ✅ 保持准确性(无虚构专长)
- ✅ 在 15 分钟内完成
- ✅ 提供清晰审计轨迹
6.9.5 对教学的启示
这个案例展示了本章所有概念的综合应用:
| 章节概念 | 案例体现 |
|---|---|
| 6.1 四层记忆模型 | 五层架构是四层模型的细化实现 |
| 6.2 上下文窗口 | 通过索引-内容分离控制加载量 |
| 6.3 压缩策略 | 会话日志只保存结构化摘要 |
| 6.4 长期记忆 | domain-expertise.md + 版本控制 |
| 6.5 情景记忆 | 决策轨迹和反思笔记 |
| 6.7 CLAUDE.md 体系 | 三层记忆位置的完整应用 |
| 6.8 四策略框架 | 缓存(稳定前缀)+ 分区(子智能体) |
概念映射:
知识管理如同资产管理:
| 笔记系统 | 金融类比 |
|---|---|
| 笔记 | 知识资产 |
| CLAUDE.md | 投资组合配置 |
| domain-expertise.md | 资产清单 |
| 定期更新 | 再平衡 |
| 版本控制 | 审计追踪 |
学习新领域给人的不只是知识累积,更是认知方式的转变。学习计量经济学后,遇到因果问题会先问「理想实验是什么?」;学习行为金融后,看到市场异常会先想「什么心理偏差在起作用?」。这种「元认知模式」的记录和传承,是 AI 副本真正有价值的地方。
讨论问题:
- 如果 Claude 永远记得和你的所有对话,会有什么好处和风险?
- 你愿意让 AI 拥有你的完整「数字记忆」吗?为什么?
- 为什么要将 Persona.md 和 domain-expertise.md 分开?
练习建议:
- 为自己的学习项目设计一个 CLAUDE.md,包含:项目概述、学习目标、已掌握知识、学习资源路径
- 创建一个「学习日志」系统,记录每次与 Claude 的学习对话摘要
- 设计一个简化版的 domain-expertise.md,列出你在不同领域的知识深度
6.10 金融应用案例
案例 6A:客户画像知识库系统
案例背景
某财富管理公司希望为 AI 理财顾问构建客户记忆系统。核心需求:
- 记住客户的风险偏好、投资目标、ESG 偏好
- 跨会话保持服务连贯性
- 追踪客户偏好的时间演化
- 满足合规审计要求
| 要素 | 说明 |
|---|---|
| 演示模式 | 长期记忆 + 情景记忆 + 三层架构 + 时间有效性 |
| 案例简述 | 设计客户偏好数据结构,实现跨会话记忆检索和风险偏好演化追踪 |
| 经济学映射 | 客户生命周期价值(CLV)—— 记忆能力提升客户留存 |
| 应用衔接 | 第 11 章舆情分析的用户画像模块采用类似设计 |
目录结构:
金融智能顾问/
├── CLAUDE.md # 项目级规则
├── clients/
│ ├── index.yaml # 客户索引
│ ├── profiles/
│ │ └── C001_张三.md # 完整画像
│ └── history/
│ └── C001/ # 交互历史(JSONL)
│ └── 2026-01.jsonl # 按月归档
├── compliance/
│ ├── suitability.md # 适当性规则
│ └── audit_trail.jsonl # 审计日志(追加式)
└── knowledge/
└── market_events/ # 市场事件记忆客户画像分层:
| 层级 | 内容 | 更新频率 | 时间有效性 | 示例 |
|---|---|---|---|---|
| 静态层 | 风险画像、投资目标 | 年度 | valid_from/valid_until | R3 平衡型、退休规划 |
| 动态层 | 持仓、近期交易 | 实时 | 当前快照 | 当前组合、最近买卖 |
| 情景层 | 交互历史 | 每次会话 | 事件时间戳 | 历史建议、客户反应 |
JSONL 审计日志示例:
{"timestamp": "2026-01-27T14:30:00Z", "customer_id": "C001", "action": "profile_update", "field": "risk_level", "old_value": "R2", "new_value": "R3", "trigger": "年度复评", "advisor_id": "A001"}
{"timestamp": "2026-01-27T14:35:00Z", "customer_id": "C001", "action": "recommendation", "product": "沪深300ETF", "amount": 100000, "rationale": "风险等级上调,增加权益配置", "suitability_check": "passed"}JSONL(JSON Lines)格式的优势:追加式写入,无需读取-修改-写入整个文件;每行独立,便于按时间范围查询;符合审计日志的最佳实践。
时间有效性设计:
客户偏好具有时间属性。一年前的风险评估不应与当前等同看待。
# C001_张三.md 中的风险画像部分
risk_profile:
current:
level: R3
score: 7
valid_from: 2026-01-15
assessment_method: questionnaire
history:
- level: R2
score: 5
valid_from: 2024-03-20
valid_until: 2026-01-14
assessment_method: questionnaire
- level: R4
score: 8
valid_from: 2023-01-10
valid_until: 2024-03-19
assessment_method: initial_onboarding
note: "首次评估,客户过高估计自身风险承受能力"截至时点查询:
合规审计时经常需要回答「在 2024 年 6 月,该客户的风险偏好是什么?」这类问题。时间有效性设计让这种查询成为可能。
客户画像的更新应该是「增量式」的——每次对话结束后,仅更新发生变化的字段,而非重写整个画像。这既节省存储,又保留了演化历史,还便于合规审计。
案例 6B:市场事件记忆与模式识别
案例背景
投资分析师经常需要回顾历史上的类似市场情景,以辅助当前决策。本案例构建市场事件记忆库,支持「历史不会重演,但会押韵」的类比分析。
| 要素 | 说明 |
|---|---|
| 演示模式 | 情景记忆 + Agentic RAG + 时间有效性 |
| 案例简述 | 建立市场事件记忆库,实现基于相似度的情景检索和历史对比分析 |
| 经济学映射 | 历史类比法——「历史不会重演,但会押韵」 |
| 应用衔接 | 第 12 章交易信号分析的市场情景识别功能 |
事件记录格式(YAML Front Matter):
# market_events/2022_fed_hike.md
---
event_id: ME_2022_FED_HIKE
timestamp: 2022-03-16T00:00:00Z
time_range: 2022-03 至 2023-07
type: monetary_policy
headline: 美联储开启加息周期
impact_level: high
affected_sectors:
- 科技
- 房地产
- 金融
market_reaction:
sp500: "-0.3%(首日),-20%(全年)"
treasury_10y: "+180bps"
advisory_implications: "减持久期敏感资产"
tags:
- 加息
- 通胀
- 紧缩
similar_events:
- "@market_events/1994_rate_hike.md"
- "@market_events/2018_rate_hike.md"
lessons_learned:
- 高通胀环境下利率敏感资产首当其冲
- 美联储「鸽转鹰」通常超出预期
---
## 详细分析
### 背景
2022年3月,美联储为应对40年最高通胀...
### 市场影响
...
### 事后复盘
...相似事件检索逻辑:
当分析师询问「当前市场环境与历史上哪个时期类似」时,系统执行:
1. 提取当前市场特征
- 货币政策环境(如:加息暂停)
- 经济状态(如:软着陆预期)
- 估值水平(如:科技股 PE)
- 市场情绪(如:谨慎乐观)
2. 与历史事件匹配
- 基于 tags 字段匹配
- 基于 type 字段筛选
- 计算特征相似度
**匹配算法**(基于标签集合的 Jaccard 相似度 + 时间距离权重):
```python
def calculate_event_similarity(current_event, historical_event):
# 1. 标签相似度(Jaccard)
common_tags = set(current_event.tags) & set(historical_event.tags)
all_tags = set(current_event.tags) | set(historical_event.tags)
tag_similarity = len(common_tags) / len(all_tags) if all_tags else 0
# 2. 时间距离惩罚
years_diff = abs(current_event.year - historical_event.year)
time_decay = 1 / (1 + years_diff * 0.1) # 每年衰减 10%
# 3. 综合得分
similarity = 0.7 * tag_similarity + 0.3 * time_decay
return similarity- 返回最相似事件
- 按相似度排序
- 展示关键差异
- 提供 lessons_learned ```
加息周期对比分析输出:
历史对比分析报告
一、当前市场与 1995-1996 年的相似性
| 维度 | 1995-1996 | 2025-2026(当前)|
|------|-----------|------------------|
| 货币政策 | 加息暂停,观望 | 加息暂停,等待数据 |
| 经济状态 | 软着陆成功 | 软着陆概率上升 |
| 通胀 | 受控 | 回落中 |
| 科技股估值 | 合理偏低 | 合理 |
二、关键差异
- AI 技术周期 vs 互联网早期
- 全球化程度不同
- 债务水平差异
三、历史启示
1995 年加息暂停确认后,标普 500 在随后 12 个月上涨约 20%。
四、风险提示
历史不会简单重演。需关注通胀反弹、地缘冲突、盈利兑现。市场事件记忆库的核心价值是「结构化历史经验」。与其依赖分析师的个人记忆,不如将历史事件系统化记录。这不仅提高检索效率,还能让新入职分析师快速获取团队的集体智慧。
6.11 本章小结
核心要点回顾
范式转变:从「存储导向」到「检索导向」——记忆的价值在于在正确时间检索正确信息,而非存储更多数据。上下文窗口是具有机会成本的经济资源。
四层记忆模型:工作记忆(上下文窗口)、短期记忆(会话历史)、长期记忆(外部存储)、情景记忆(决策轨迹)各司其职,形成完整的记忆体系。
U 型注意力曲线:模型注意力在上下文开头和结尾最强,中间区域召回率下降 10-40%。关键信息应放在开头(系统提示)和结尾(当前任务)。
10 倍成本差异:缓存命中的 tokens 成本仅为未缓存的 1/10。设计缓存友好的提示结构是成本优化的关键杠杆。
压缩的代价:递归摘要仅 35.3% 准确率。结构化摘要通过强制保留关键字段,比自由摘要更可靠。
三层信息架构:L1(元数据,始终加载)→ L2(指令,按需加载)→ L3(数据,即时加载),可节省 87% token 消耗。
四策略框架:缓存优化(预防)→ 观察遮蔽(早期干预)→ 压缩策略(主动管理)→ 分区策略(架构解决),形成层层防御。
Agentic RAG:从被动检索进化为主动决策。GraphRAG 在关系推理场景下准确率提升 20-35%,减少 30% 幻觉。
自我进化:五层记忆架构 + 自动化更新流程,让 AI 副本能够持续学习和演化。
记忆管理成长路径
入门阶段 - 熟练使用 /compact 和 /clear 命令 - 理解 CLAUDE.md 的三层结构(用户级/项目级/子目录级) - 能在任务节点主动压缩对话
进阶阶段 - 设计三层信息架构(L1/L2/L3) - 使用带指令的 /compact 精确控制保留内容 - 创建文件式长期记忆(WORKING_PLAN.md、REMEMBER.md) - 实施缓存优化策略
精通阶段 - 设计分层记忆架构(短期/中期/长期) - 实施四策略框架进行上下文优化 - 为团队制定上下文管理规范 - 构建具有自我进化能力的智能体记忆系统
下一章预告
第 7 章「工具扩展」将介绍如何通过 MCP 协议和外部工具扩展智能体能力,包括金融数据 API 接入、自定义工具开发和 Plugin 系统。工具输出的记忆管理将直接应用本章的观察遮蔽策略——毕竟,工具输出占据了 83.9% 的 tokens。